Pandas

pandas는 고 수준의 자료구조와 파이썬을 통한 빠르고 쉬운 데이터 분석 도구를 포함하고 있다.
- 명시적으로 축의 이름에 따라 데이터를 정렬할 수 있는 자료 구조를 제공한다.
- 누락된 데이터를 유연하게 처리를 할 수 있다.
- SQL과 같은 일반 데이터베이스처럼 데이터를 합치고 관계연산을 수행 할 수 있다.
1. Series
- 일렬의 객체를 담을 수 있는 1차원 백터
- 왼쪽에 색인을 보여주고 오른쪽에 해당 색의 값을 보여준다.

import pandas as pd
import numpy as np
obj = pd.Series([4,7,-5,3], index=['d', 'b', 'a', 'c'])
print(obj)
print('\n', obj.values)
print('\n', type(obj.values))
print('\n', obj.index)
print('\n',obj['a'])
print('\n',obj[['a', 'c']])
print('\n', obj[obj>0])
print('\n', obj*2)
print('\n', np.exp(obj))
2. DataFrame
- 표 값은 스프레드시트 형식의 자료 구조
- 2 차원 데이터
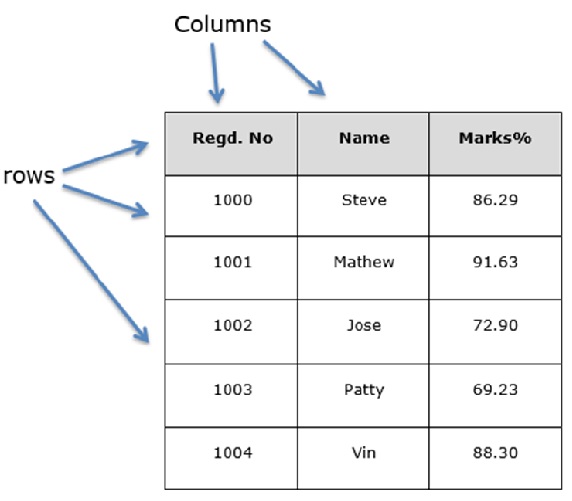
2.1 DataFrame 생성
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(8).reshape(4, 2),
index=['a', 'b', 'c', 'd'],
columns=['one', 'two'])
print(df)
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [200, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
frame = pd.DataFrame(data)
print('\n',frame)
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop'])
print('\n',frame2)
frame3 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two','three','four', 'five', 'six'])
print('\n',frame3)
print('\n',frame3.year) # Series를 리턴한다.
print('\n',frame3['year']) # 행을 추출한다.
print('\n', frame3.loc['three']) # 열을 추출한다.
'''
one two
a 0 1
b 2 3
c 4 5
d 6 7
state year pop
0 Ohio 200 1.5
1 Ohio 2001 1.7
2 Ohio 2002 3.6
3 Nevada 2001 2.4
4 Nevada 2002 2.9
5 Nevada 2003 3.2
year state pop
0 200 Ohio 1.5
1 2001 Ohio 1.7
2 2002 Ohio 3.6
3 2001 Nevada 2.4
4 2002 Nevada 2.9
5 2003 Nevada 3.2
year state pop debt
one 200 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN
six 2003 Nevada 3.2 NaN
one 200
two 2001
three 2002
four 2001
five 2002
six 2003
Name: year, dtype: int64
one 200
two 2001
three 2002
four 2001
five 2002
six 2003
Name: year, dtype: int64
year 2002
state Ohio
pop 3.6
debt NaN
Name: three, dtype: object
...
행을 추출 할 때에는 dataframe[
column명] 열을 추출 할 때에는 dataframe.loc[‘index명’]
3. 핵심 기능
3.1 Reindexing
import pandas as pd
import numpy as np
obj = pd.Series([4, 7, -5, 3], index=list('dbac'))
print(obj)
obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e'])
print('\n', obj2)
obj3 = pd.Series(['blue', 'purple', 'yellow'], index=[0, 2, 4])
print('\n', obj3)
print('\n', obj3.reindex(np.arange(6), method='ffill')) # NaN 값을 바로 앞에 있는 값으로 대체
frame = pd.DataFrame(np.arange(9).reshape(3, 3),
index=list('acd'),
columns=['Ohio', 'Texas', 'Califonia'])
print('\n', frame)
print('\n', frame.reindex(['a', 'b', 'c', 'd']))
print('\n', frame.reindex(columns=['Texas', 'Utah', 'Ohio']))
'''
d 4
b 7
a -5
c 3
dtype: int64
a -5.0
b 7.0
c 3.0
d 4.0
e NaN
dtype: float64
0 blue
2 purple
4 yellow
dtype: object
0 blue
1 blue
2 purple
3 purple
4 yellow
5 yellow
dtype: object
Ohio Texas Califonia
a 0 1 2
c 3 4 5
d 6 7 8
Ohio Texas Califonia
a 0.0 1.0 2.0
b NaN NaN NaN
c 3.0 4.0 5.0
d 6.0 7.0 8.0
Texas Utah Ohio
a 1 NaN 0
c 4 NaN 3
d 7 NaN 6
'''
3.2 데이터 삭제(제외)
- Row나 Column을 제외하기 위해 Drop api를 사용한다.
- 원본은 변경이 되지 않는다.
import pandas as pd
import numpy as np
obj = pd.Series(np.arange(5.), index=['a','b','c', 'd', 'e'])
print(obj)
new_obj = obj.drop('c')
print('\n', new_obj)
print('\n', obj.drop(['d','c']))
data = pd.DataFrame(np.arange(16).reshape(4,4),
index=['Ohio', 'Colorado', 'Utah', 'New york'],
columns=['one', 'two', 'three', 'four'])
print('\n',data)
print('\n', data.drop(['Colorado', 'Ohio']))
print('\n',data.drop('two', axis=1))
print('\n',data.drop(['two', 'four'], axis='columns'))
3.3 색인, 선택, 거르기
- Series의 색인은 정수로 접근이 가능하고 column name으로 도 접근이 가능하다.
import pandas as pd
import numpy as np
obj = pd.Series(np.arange(4.), index=['a', 'b', 'c', 'd'])
print('\n', obj)
print('\n', obj['b'])
print('\n', obj[1])
print('\n', obj[2:4])
print('\n', obj[['b','a','d']])
print('\n', obj[[1,3]])
print('\n', obj[obj<2])
print('\n', obj['b':'c'])
obj['b':'c'] = 5
print('\n', obj)
'''
a 0.0
b 1.0
c 2.0
d 3.0
dtype: float64
1.0
1.0
c 2.0
d 3.0
dtype: float64
b 1.0
a 0.0
d 3.0
dtype: float64
b 1.0
d 3.0
dtype: float64
a 0.0
b 1.0
dtype: float64
b 1.0
c 2.0
dtype: float64
a 0.0
b 5.0
c 5.0
d 3.0
dtype: float64
'''
3.3.1 iloc[]
data = pd.DataFrame(np.arange(16).reshape(4,4),
index=['Ohio', 'Colorado', 'Utah', 'New york'],
columns=['one', 'two', 'three','four'])
print(data)
print('\n', data.iloc[1,2]) # Data만 가져 온다. 색인은 제외
print('\n', data.iloc[1,[0,2,3]]) # Series를 가져 온다
print('\n', data[data['three'] > 5])
print('\n', data.iloc[:, :3][data['three'] >5])
# 앞의 대괄호 연산부터 수행하고 그 결과 값을 뒤의 대괄호가 처리한다
3.4 산술 연산
- Pandas에서 중요한 기능은 다른 객체간의 산술 연산이다.
- 객체를 연산 할 때 짝이 맞지 않는 색인 있다면 결과에 두 색인이 통합된다.
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.arange(12.).reshape((3, 4)), columns=list('abcd'))
df2 = pd.DataFrame(np.arange(20).reshape(4, 5), columns=list('abcde'))
print('\n', df1, '\n')
print('\n', df2, '\n')
print('\n', df1 + df2, '\n')
# 짝이 맞지 않은 색인에 대해서는 NaN으로 셋이 된다.
'''
a b c d e
0 0.0 2.0 4.0 6.0 NaN
1 9.0 11.0 13.0 15.0 NaN
2 18.0 20.0 22.0 24.0 NaN
3 NaN NaN NaN NaN NaN
'''
print('\n', df1.add(df2, fill_value = 0), '\n')
# 짝이 맞지 않은 색인에 대해서 fill_value로 set이 된다.
3.5 함수 적용과 맵핑
- Pandas 객체에도 유니버셜 함수를 적용할 수 있다.
import pandas as pd
import numpy as np
np.random.seed(12345)
frame = pd.DataFrame(np.random.randn(4,3),
columns=list('bde'),
index=['Utah', 'Ohio', 'Oregon', 'Texas'])
print(frame)
f = lambda x : x.max() - x.min()
print('\n', frame.apply(f))
print('\n', frame.apply(f, axis=1))
def f1(x):
return pd.Series([x.min(), x.max()], index=['min','max'])
print('\n', frame.apply(f1))
print('\n', frame.apply(f1 ,axis=1))
'''
b d e
Utah -0.204708 0.478943 -0.519439
Ohio -0.555730 1.965781 1.393406
Oregon 0.092908 0.281746 0.769023
Texas 1.246435 1.007189 -1.296221
b 1.802165
d 1.684034
e 2.689627
dtype: float64
Utah 0.998382
Ohio 2.521511
Oregon 0.676115
Texas 2.542656
dtype: float64
b d e
min -0.555730 0.281746 -1.296221
max 1.246435 1.965781 1.393406
min max
Utah -0.519439 0.478943
Ohio -0.555730 1.965781
Oregon 0.092908 0.769023
Texas -1.296221 1.246435
'''
3.6 Sorting
import pandas as pd
import numpy as np
obj = pd.Series(np.arange(4) , index=list('dabc'))
print(obj)
print('\n', obj.sort_index())
frame = pd.DataFrame(
np.arange(8).reshape(2,4),
index=['three','one'],
columns= list('dabc')
)
print('\n', frame)
print('\n', frame.sort_index())
print('\n', frame.sort_index(axis=1, ascending = False))
obj = pd.Series([4,7,-5,2])
print('\n', obj.sort_values())
frame2 = pd.DataFrame({'b' : [4,7,5,-2], 'a' : [0,1,0,1]})
print('\n', frame2.sort_values(by='b'))
print('\n', frame2.sort_values(by=['a', 'b']))
# a 기준으로 먼저 소팅 한 후 같은 a에 대해서 b 값 기준으로 다시 소팅
3.7 기술 통계 계산과 요약
import pandas as pd
import numpy as np
np.random.seed(12345)
data = pd.DataFrame(
np.random.rand(100, 2),
columns=['one', 'two'])
print(data.sum())
print('\n', data.sum(axis=1))
print('\n', data.describe())
print('\n', data.info())
print('\n', data.head(5)) # 맨 앞 5개
print('\n', data.tail(5)) # 맨 뒤 5개
3.8 누락된 데이터 처리
- Pandas의 설계 목표 증 하나는 누락 데이터를 쉽게 처리하는 것이다.
import pandas as pd
import numpy as np
data = pd.Series([1,np.nan,3, np.nan,7])
print(data)
print('\n',data.dropna())
df = pd.DataFrame(np.random.randn(7,3))
df.iloc[:4,1] = np.nan
df.iloc[:2,2] = np.nan
print('\n', df)
print('\n', df.fillna(0))
print('\n', df.fillna({1:0.5, 2:-1})) # Dictionary를 이용하여
print('\n', df.fillna(method='backfill')) # 뒤에 있는 값을 대치
4. Data Loading
4.1 CSV
import pandas as pd
import numpy as np
df = pd.read_csv('ex1.csv')
print(df)
df1 = pd.read_csv('ex2.csv', header=None) # Header를 자동 생성
print('\n',df1)
df2 = pd.read_csv('ex2.csv',names=['one', 'two', 'three', 'four', 'five'])
print('\n',df2)
df3 = pd.read_csv('ex2.csv',names=['one', 'two', 'three', 'four', 'five'],
index_col='five')
print('\n',df3)
df4 = pd.read_csv('csv_mindex.csv', index_col=['key1', 'key2']) # 멀티 인덱스
print('\n',df4)
df5 = pd.read_csv('ex4.csv', skiprows=[0,2,3]) # 특정 열을 skip
print('\n', df5)
chunker = pd.read_csv('ex6.csv', chunksize=1000)
tot = pd.Series([])
for piece in chunker:
tot = tot.add(piece['key'].value_counts(), fill_value =0)
tot = tot.sort_values(ascending=False)
print('\n',tot[:10])
5. Data 변형 및 치환
5.1. 데이터베이스 스타일로 DataFrame 합치기
5.1.1 merge()
- DB의
join연산과 동작 방식이 동일 하다.
import pandas as pd
import numpy as np
import json
df1 = pd.DataFrame({'key' : ['b','b','a', 'c', 'a', 'a', 'b'], 'data1' :range(7)})
df2 = pd.DataFrame({'key' : ['a', 'b', 'd'], 'data2' :range(3)})
print('\n',df1, '\n')
print('\n',df2, '\n')
print('\n',pd.merge(df1, df2), '\n')
print('\n',pd.merge(df1, df2, on = 'key'), '\n')
# join 기본으로 inner join이다.
#how를 통하여 어떤 join을 할 지를 선택 할 수 있다.
print('\n how')
print('\n',pd.merge(df1, df2, how = 'outer'), '\n') # outer join
print('\n',pd.merge(df1, df2, how = 'left'), '\n') # left join
print('\n',pd.merge(df1, df2, how = 'right'), '\n') # right join
print('\n',pd.merge(df1, df2, how = 'inner'), '\n') # inner join
left = pd.DataFrame({
'key1' :['foo', 'foo','bar'],
'key2': ['one', 'two', 'one'],
'lval': [1,2,3]
})
right = pd.DataFrame({
'key1' :['foo','foo', 'bar','bar'],
'key2': ['one', 'one', 'one', 'two'],
'rval': [4,5,6,7]
})
print('\n',left, '\n')
print('\n',right, '\n')
print('\n',pd.merge(left, right, on =['key1', 'key2'], how='outer'), '\n')
df1 = pd.DataFrame({'아이디' : [12,13,14,15,16],
'이름' : ['a','b','c','d','e'],
'생일' : [1111,2222,3333,4444,5555],
'취미' : ['h1','h2','h3','h4','h5'],
'주소' : ['add1','add2','add3','add4','add5']})
df2 = pd.DataFrame({'부모 생일' : [22,33,44,55,66],
'성명' : ['a','b','c','d','e'],
'동생' : [True,False,True,False,True],
'좌우명' : ['h1','h2','h3','h4','h5'],
'특기' : ['add1','add2','add3','add4','add5']})
print('\n',df1)
print('\n',df2)
print('\n',pd.merge(df1, df2, left_on='이름', right_on="성명", how='outer'), '\n')
# join을 할 때 사용될 key를 left_on, right_on으로 직접 지정 할 수 있다.
5.1.2 concat()
s1 = pd.Series([0,1], index=list('ab'))
s2 = pd.Series([2,3,4], index=list('cde'))
s3 = pd.Series([5,6], index=list('fg'))
print(s1,'\n')
print(s2,'\n')
print(s3,'\n')
print(pd.concat([s1,s2,s3]))
print(pd.concat([s1,s2,s3], axis=1, sort= False))
s4= pd.concat([s1*5, s3])
print(s4,'\n')
print(pd.concat([s1,s4], axis=1, sort= False))
print(pd.concat([s1,s4], axis=1, join='inner'))
DataFrame을 붙일 때 index가 불일치 하는 경우 NaN 값이 들어가기 때문에 주의하여 사용해야 한다.
5.2 데이터 회전(stack(), unstack())
- Column과 index의 위치를 서로 바꿈으로써 같은 데이터를 여려 가지 모습(표현)으로 분석이 가능하다.
- pivot을 통해 그룹화를 쉽게 할 수 있다.
import pandas as pd
import numpy as np
data = pd.DataFrame(np.arange(6).reshape(2,3),
index=pd.Index(['Ohio', 'Colorado'], name = 'state'),
columns=pd.Index(['one', 'two','three'], name ='number'))
# name을 사용하여 index나 column의 title을 지정할 수 있다.
print(data)
result = data.stack() # column을 index로 이동한다.
print('\n',result)
print('\n',result.unstack()) # index를 column으로 이동한다.
print('\n',result.unstack(level =0)) # unstack()과 동일하다
print('\n',result.unstack(level =1))
print('\n',result.unstack('state'))
s1 = pd.Series([0,1,2,3], index=list('abcd'))
s2 = pd.Series([4,5,6], index=list('cde'))
data2 = pd.concat([s1, s2], keys=['one', 'two']) # index 의 레벨이 2개가 생긴다.
print('\n',data2)
print('\n',data2.unstack())
frame = pd.DataFrame({'a':range(7),'b':range(7,0,-1),
'c':['one','one','one','two','two','two','two'],
'd':[0,1,2,0,1,2,3]})
print('\n',frame)
frame2 = frame.set_index(['c','d']) # column을 인덱스로 지정할 수 있다.
print('\n',frame2)
'''
number one two three
state
Ohio 0 1 2
Colorado 3 4 5
state number
Ohio one 0
two 1
three 2
Colorado one 3
two 4
three 5
dtype: int32
number one two three
state
Ohio 0 1 2
Colorado 3 4 5
state Ohio Colorado
number
one 0 3
two 1 4
three 2 5
number one two three
state
Ohio 0 1 2
Colorado 3 4 5
state Ohio Colorado
number
one 0 3
two 1 4
three 2 5
one a 0
b 1
c 2
d 3
two c 4
d 5
e 6
dtype: int64
a b c d e
one 0.0 1.0 2.0 3.0 NaN
two NaN NaN 4.0 5.0 6.0
'''
5.3 중복 제거
import pandas as pd
import numpy as np
data = pd.DataFrame({'k1' : ['one'] * 3 + ['two'] * 4 + ['one'],
'k2' : [1,1,2,3,3,4,4,1]})
# 맨 위에서 부터 순차적으로 비교하기 때문에 맨 처음은 무조건 False이다.
print(data)
print('\n',data.duplicated())
print('\n', data.drop_duplicates())
print('\n', data.drop_duplicates(['k1']))
'''
k1 k2
0 one 1
1 one 1
2 one 2
3 two 3
4 two 3
5 two 4
6 two 4
7 one 1
0 False
1 True
2 False
3 False
4 True
5 False
6 True
7 True
dtype: bool
k1 k2
0 one 1
2 one 2
3 two 3
5 two 4
k1 k2
0 one 1
3 two 3
'''
5.4 함수 매핑을 이용한 데이터 변형 - map()
import pandas as pd
import numpy as np
data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon', "Pastrami", 'corned beef', 'Bacon', 'pastrami',
'honey ham', 'nova lox'],
'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
print('\n', data, '\n')
meat_to_animal = {
'bacon' : 'pig',
'pulled pork' : 'pig',
'pastrami' : 'cow',
'corned beef' : 'cow',
'honey ham' : 'pig',
'nova lox' : 'salmon'
}
data['animal'] = data['food'].map(str.lower).map(meat_to_animal)
print('\n',data, '\n')
print('\n',data['food'].map(lambda x : meat_to_animal[x.lower()]), '\n')
'''
food ounces
0 bacon 4.0
1 pulled pork 3.0
2 bacon 12.0
3 Pastrami 6.0
4 corned beef 7.5
5 Bacon 8.0
6 pastrami 3.0
7 honey ham 5.0
8 nova lox 6.0
food ounces animal
0 bacon 4.0 pig
1 pulled pork 3.0 pig
2 bacon 12.0 pig
3 Pastrami 6.0 cow
4 corned beef 7.5 cow
5 Bacon 8.0 pig
6 pastrami 3.0 cow
7 honey ham 5.0 pig
8 nova lox 6.0 salmon
0 pig
1 pig
2 pig
3 cow
4 cow
5 pig
6 cow
7 pig
8 salmon
Name: food, dtype: object
'''
5.5 치환 - replace()
import pandas as pd
import numpy as np
data = pd.Series([1, -999., 2.,-1000,3])
print('\n', data, '\n')
print('\n', data.replace([-999, -1000], np.nan), '\n') # list와 일치하는 것을 치환
print('\n', data.replace({-999:0, -1000:np.nan}), '\n') # map을 이용
5.1.7 축 색인 이름 바꾸기
import pandas as pd
import numpy as np
data = pd.DataFrame(
np.arange(12).reshape(3,4),
index=['Ohio', 'Colorado','New York'],
columns=['one', 'two', 'three', 'four']
)
print(data.index.map(str.upper), '\n')
data.index = data.index.map(str.upper)
print(data, '\n')
print(data.rename(index =str.title, columns=str.upper), '\n')
print(data.rename(index ={'OHIO' : 'INDIANA'}, columns={'three' : 'peek'}), '\n')
5.6 cut()
import pandas as pd
ages = [20,22,25,27,21,23,36,31,55,42,32]
bins = [18,25,35,60, 100]
cData = pd.cut(ages, bins)
print(cData)
print('\n',pd.value_counts(cData))
group_nams = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
rcData= pd.cut(ages, bins, labels=group_nams)
print('\n',rcData)
print('\n', pd.value_counts(rcData))
'''
[(18, 25], (18, 25], (18, 25], (25, 35], (18, 25], ..., (35, 60], (25, 35], (35, 60], (35, 60], (25, 35]]
Length: 11
Categories (4, interval[int64]): [(18, 25] < (25, 35] < (35, 60] < (60, 100]]
(18, 25] 5
(35, 60] 3
(25, 35] 3
(60, 100] 0
dtype: int64
[Youth, Youth, Youth, YoungAdult, Youth, ..., MiddleAged, YoungAdult, MiddleAged, MiddleAged, YoungAdult]
Length: 11
Categories (4, object): [Youth < YoungAdult < MiddleAged < Senior]
Youth 5
MiddleAged 3
YoungAdult 3
Senior 0
dtype: int64
'''
5.8 GroupBy
- 분류 - 적용 - 결합
- 데이터를 색인 기준으로 분리한다.
- 함수를 각 그룹에 적용시켜 새로운 값을 얻어낸다.
- 함수를 적용한 결과를 하나의 객체로 나타낸다.
5.8.1 공통의 이름으로 그룹화
import pandas as pd
import numpy as np
np.random.seed(12345)
df= pd.DataFrame({'key1' : ['a', 'a','b', 'b', 'a' ],
'key2' : ['one','two', 'one', 'two', 'one'],
'data1': np.random.randn(5),
'data2' : np.random.randn(5)})
print(df)
grouped = df['data1'].groupby(df['key1'])
print('\n',grouped)
print('\n', grouped.mean())
print('\n', df['data1'].groupby([df['key1'], df['key2']]).mean())
print('\n', df['data1'].groupby([df['key1'], df['key2']]).mean().unstack())
for name, group in df.groupby('key1'):
print('name:' , name)
print(group)
print('\n')
for (n1, n2), grouped in df.groupby(['key1', 'key2']) :
print(n1 ,n2)
print(group)
dData = dict(list(df.groupby(['key1'])))
print('\n', dData['b'])
5.8.2 임의의 이름을 사용하여 그룹화
import pandas as pd
import numpy as np
people = pd.DataFrame(np.random.randn(5, 5),
index=['Joe', "Steve", 'Wes', 'jim', 'Travis'],
columns=list('abcde')
)
people.loc[2:3, ['b','c']] = np.nan
print(people,'\n')
mapping = {'a' : 'red', 'b': 'red', 'c' : 'blue', 'd' : 'blue', 'e' : 'red'}
cData = people.groupby(mapping, axis=1)
fData = cData.sum()
print('\n', fData)
print('\n', people.groupby(len).sum()) # 사람 이름 길이로 그룹화
'''
a b c d e
Joe -0.899854 -0.017575 0.206386 0.123286 -2.492479
Steve -0.342711 0.532649 0.728005 0.598896 0.420379
Wes 1.171489 NaN NaN -0.997370 1.445726
jim 1.867852 -1.200307 1.045335 0.643594 -1.831577
Travis 0.513562 -0.712097 0.539612 -1.682141 -0.504461
blue red
Joe 0.329672 -3.409908
Steve 1.326900 0.610317
Wes -0.997370 2.617215
jim 1.688929 -1.164032
Travis -1.142529 -0.702996
a b c d e
3 2.139487 -1.217882 1.251721 -0.230490 -2.878330
5 -0.342711 0.532649 0.728005 0.598896 0.420379
6 0.513562 -0.712097 0.539612 -1.682141 -0.504461
'''
5.8.3 agg()
- 집계 함수이다.
- max, count, mean, min 등 다양한 연산을 지원한다.
import pandas as pd
import numpy as np
tips = pd.read_csv('tips.csv')
print(tips.head(5))
tips['tip_pct'] = tips['tip'] / tips['total_bill']
print('\n',tips.head(5))
grouped = tips.groupby(['sex', 'smoker'])
grouped_pct = grouped['tip_pct']
print('\n', grouped_pct.agg('mean'))
print('\n', grouped_pct.agg(['mean', 'std']))
print('\n', grouped_pct.agg([('gmean' , 'mean'), ('gstd','std')]))
print('\n', grouped.agg({'tip' : np.max, 'size' : 'sum'}))
print('\n', grouped.agg({'tip_pct' : ['min', 'max', 'mean','std'], 'size' : 'sum'}))
5.8.4 apply()
- groupBy 함수이다.
- agg() 는 미리 정의가 된 연산이지만 apply에 함수 포인터를 넘겨 줌으로써 좀 더 자유로운 연산이 가능하다.
tips = pd.read_csv('tips.csv')
tips['tip_pct'] = tips['tip'] / tips['total_bill']
def top(df, n= 5, column = 'tip_pct') :
return df.sort_values(by= column)[-n:]
print('\n',top(tips, n= 6), '\n')
print('\n',tips.groupby('smoker').apply(top), '\n')
print('\n',tips.groupby(['smoker', 'day']).apply(top, n =1, column='total_bill'), '\n')
result = tips.groupby('smoker')['tip_pct'].describe()
print('\n', result)
print('\n', result.unstack())
5.9 Pivot Table
- 피벗 테이블은 하나 이상의 키로 수집하여 로우, 칼럼에 나열하여 데이터를 정렬한다.
import pandas as pd
import numpy as np
tips = pd.read_csv('tips.csv')
print(tips.head(5))
tips['tip_pct'] = tips['tip'] / tips['total_bill']
print('\n', tips.pivot_table(index=['sex', 'smoker']))
print('\n', tips.pivot_table(
['tip_pct', 'size'],
index=['sex', 'day'],
columns='smoker'
))
print('\n', tips.pivot_table(
'tip_pct',
index=['sex', 'smoker'],
columns='day',
aggfunc = len
))
'''
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
size tip tip_pct total_bill
sex smoker
Female No 2.592593 2.773519 0.156921 18.105185
Yes 2.242424 2.931515 0.182150 17.977879
Male No 2.711340 3.113402 0.160669 19.791237
Yes 2.500000 3.051167 0.152771 22.284500
size tip_pct
smoker No Yes No Yes
sex day
Female Fri 2.500000 2.000000 0.165296 0.209129
Sat 2.307692 2.200000 0.147993 0.163817
Sun 3.071429 2.500000 0.165710 0.237075
Thur 2.480000 2.428571 0.155971 0.163073
Male Fri 2.000000 2.125000 0.138005 0.144730
Sat 2.656250 2.629630 0.162132 0.139067
Sun 2.883721 2.600000 0.158291 0.173964
Thur 2.500000 2.300000 0.165706 0.164417
day Fri Sat Sun Thur
sex smoker
Female No 2.0 13.0 14.0 25.0
Yes 7.0 15.0 4.0 7.0
Male No 2.0 32.0 43.0 20.0
Yes 8.0 27.0 15.0 10.0
'''
5.10 Matplotlib을 활용한 예
import pandas as pd
fec = pd.read_csv('P00000001-ALL.csv')
print('\n', fec.info())
print('\n', fec['cand_nm'].drop_duplicates().values)
parties = {'Bachmann, Michelle':'Republican',
'Cain, Herman':'Republican',
'Gingrich, Newt':'Republican',
'Huntsman, Jon':'Republican',
'Johnson, Gary Earl':'Republican',
'McCotter, Thaddeus G':'Republican',
'Obama, Barack':'Democrat',
'Paul, Ron':'Republican',
'Pawlenty, Timothy':'Republican',
'Perry, Rick':'Republican',
"Roemer, Charles E. 'Buddy' III":'Republican',
'Romney, Mitt':'Republican',
'Santorum, Rick':'Republican'}
fec['party'] = fec.cand_nm.map(parties)
print(fec.head(10))
print('\n', fec['party'].value_counts())
fec_mrbo = fec[fec.cand_nm.isin(['Obama, Barack', 'Romney, Mitt'])]
print('\n',fec_mrbo )
# 기부금이 0 이상인 Data
fec = fec[fec.contb_receipt_amt >0]
print(fec.head(10))
occ_mapping = {
'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED',
'INFORMATION REQUESTED':'NOT PROVIDED',
'INFORMATION REQUESTED (BEST EFFORTS)':'NOT PROVIDED',
'C.E.O.':'CEO',
'C.E.O':'CEO'
}
# 의미가 같지만 용어가 다른 data를 변환한다.
f = lambda x: occ_mapping.get(x,x) # get(key, default value)
fec.contbr_occupation = fec.contbr_occupation.map(f)
emp_mapping = {
'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED',
'INFORMATION REQUESTED':'NOT PROVIDED',
'SELF':'SELF-EMPLOYED',
'SELF EMPLOYED':'SELF-EMPLOYED'
}
# 의미가 같지만 용어가 다른 data를 변환한다.
f = lambda x: emp_mapping.get(x,x)
fec.contbr_employer = fec.contbr_employer.map(f)
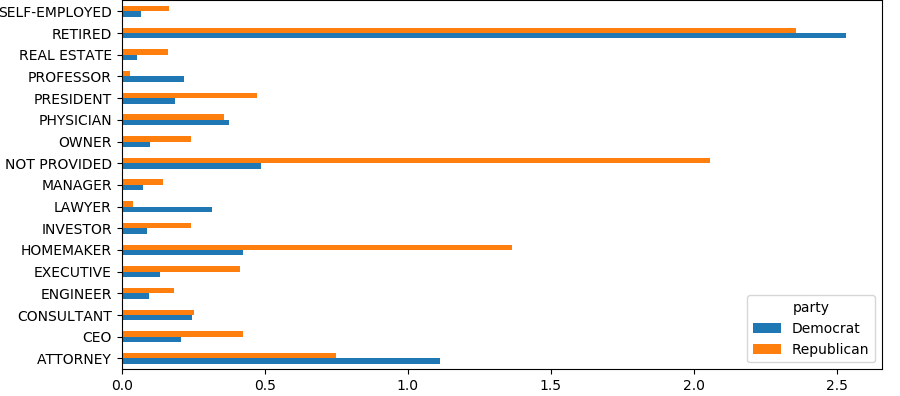
by_occupation = fec.pivot_table('contb_receipt_amt',
index = 'contbr_occupation'
,columns = 'party',
aggfunc= 'sum')
print('\n', by_occupation)
over_2mm = by_occupation[by_occupation.sum(axis =1) > 2000000]
print('\n', over_2mm)
import matplotlib.pyplot as plt
# Bar 그래프로 변환
over_2mm.plot(kind ='barh')
plt.show()
def get_to_amount(group, key, n=5) :
totals = group.groupby(key)['contb_receipt_amt'].sum()
return totals.sort_values(ascending=False)[:n]
grouped = fec_mrbo.groupby('cand_nm')
print('\n', grouped.apply(get_to_amount, 'contbr_occupation', n =7))
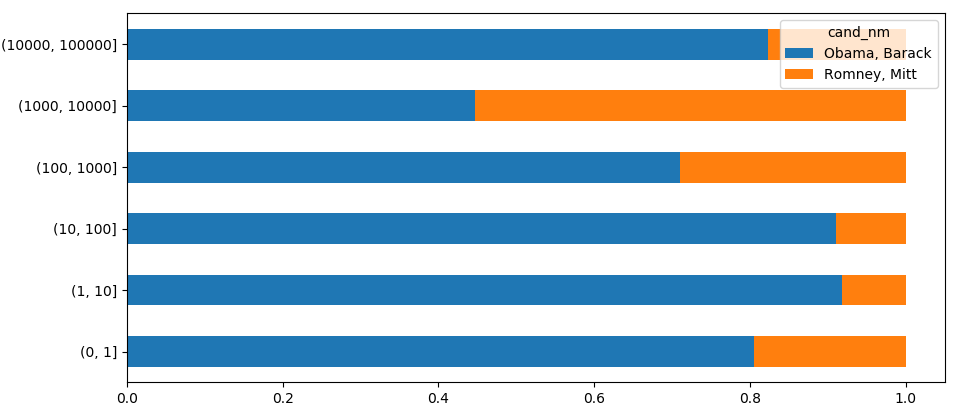
# Data를 구간 별로 나눔
bins = [0,1,10,100,1000,10_000,100_000, 1_000_000,10_000_000]
labels = pd.cut(fec_mrbo.contb_receipt_amt,bins)
print(labels)
# 후원자의 카운트를 그륩화한다.
grouped = fec_mrbo.groupby(['cand_nm', labels])
print('\n', grouped.size())
print('\n', grouped.size().unstack(level=0))
bucket_sums = grouped.contb_receipt_amt.sum().unstack(level=0)
print('\n', bucket_sums)
# Data를 오바마와 롬니의 비율로 변환
normed_sums= bucket_sums.div(bucket_sums.sum(axis=1), axis = 0)
print('\n', normed_sums)
normed_sums[0:-2].plot(kind='barh', stacked = True)
plt.show()
- 실행 결과
| 두 후보에 대해서 직업 별 기부금 양 | 기부금 총 양에 대한 두 후보의 비율 |
|---|---|
 |
 |
6. 시계열 data 처리
- 시게열 데이터는 금융, 경제, 생태학, 물리학 등 여러 분야에서 사용되는 매우 중요한 구조화 된 데이터이다.
- 시간 상의 여러지점을 관측하거나 측정할 수 있는 모든 것이 시계열이다.
- 시간 내에서 특정 순간의 타임 스탬프
- 2018년 9월이나 2017년 같은 고정된 시간
- 실험 혹은 경과 시간
6.1 날짜, 시간 자료형
from datetime import datetime
now = datetime.now()
print(now,'\n')
print('{}년 {}월 {}일'.format(now.year, now.month, now.day), '\n')
delta = datetime(2018,1,7) - datetime(2015,6,24,8,15)
print(delta, '\n')
print('days:{} seconds : {}'.format(delta.days, delta.seconds), '\n')
from datetime import timedelta
start = datetime(2011,1,7)
print(start + timedelta(12), '\n')
print(start -2 * timedelta(12), '\n')
6.2 datetime format
from datetime import datetime
import pandas as pd
import numpy as np
dates = [datetime(2017, 1, 2), datetime(2017, 1, 5), datetime(2017, 7, 2),
datetime(2017, 9, 2), datetime(2017, 10, 2), datetime(2017, 12, 2)]
ts = pd.Series(np.random.randn(6), index=dates)
print('\n', ts)
print('\n', type(ts))
# 다양햔 형태로 인덱스 접근
print(ts['1/5/2017'])
print(ts['20171202'])
l_ts = pd.Series(np.random.randn(1000)
, index=pd.date_range('1/1/2010', periods=1000)) # 2010월 1월 1일 부터 1일 증가 한 데이터를 가져온다.
print(l_ts)
print(l_ts['2011'], '\n') # 2011 년도 데이터
print(l_ts['2011-05'], '\n') # 2011년 5월 데이터
print(l_ts['2011-05' : '2011-07'], '\n') # 2011년 5월 부터 7월 데이터
dates = pd.date_range('1/1/2010', periods=100, freq='W-WED') #수요일 데이터만 추출
df = pd.DataFrame(np.random.randn(100,4),
index=dates,
columns=['one', 'two', 'three', 'four'])
print('\n', df)
print('\n', pd.date_range('1/1/2011', '10/2/2011'))
print(pd.date_range(start='2011-01-01', periods=10))
#start에서 뒤로 10개 생성
print(pd.date_range(end='2011-01-01', periods=10))
#end에서 잎으로 10개 생성
print(pd.date_range(start='2011-01-01', end='2011-12-01', freq='BM'))
# 그 달의 마지막 날 생성
print('\n', pd.date_range(start='2011-01-01', end='2011-12-01', freq='WOM-2FRI'))
# 그 달의 두 번째 주 금요일 생성
print('\n', pd.date_range(start='2011-01-01', end='2011-12-01', freq='1h30min'))
# 1시간 30분 간격으로 생성
freq의 활용도가 매우 높으므로 지원하는 형식을 잘 알아두면 좋다. 예를 들어 비즈니스 데이(월~금)만 생성이 가능하다.
6.3 Sampling
import pandas as pd
import numpy as np
np.random.seed(12345)
rng = pd.date_range('1/1/2000', periods=100, freq='D')
ts = pd.Series(np.random.rand(100), index=rng)
print(ts)
print(ts.resample('M').mean())
# 해당 달의 평균을 구한다. 그룹핑과 동일
rng = pd.date_range('1/1/2000', periods=12, freq ='T')
ts = pd.Series(np.arange(12), index=rng)
# Down sampling
print('\n', ts)
print('\n', ts.resample('5min').sum())
#5분 단위로 샘플링, 디폴트로 오른쪽 미 포함
print('\n', ts.resample('5min', closed='right').sum())
# left를 제외하고 right를 포함한다.
print('\n', ts.resample('5min', closed = 'right', label='right').sum())
# label를 변경
frame = pd.DataFrame(np.random.rand(2,4),
index= pd.date_range('1/1/2000', periods=2, freq='W-WED'))
# Up sampling
print('\n', frame)
print('\n', frame.resample('D').ffill()) # day 기준으로 sample을 늘린다.
print('\n', frame.resample('D').ffill(limit=2))
6.4 시계열 정보와 Matplotlib을 활용한 예
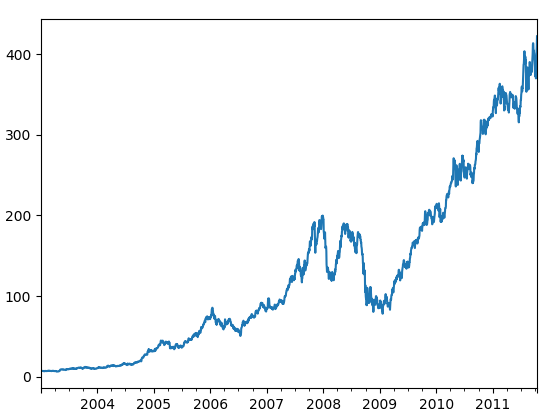
import pandas as pd
import matplotlib.pyplot as plt
close_px_all = pd.read_csv('stock_px.csv', parse_dates=True, index_col=0)
# parse_dates = True: 시간 형식 data가 있으면 date로 생성한다.
# index_col=0 : 첫번째 컬럼을 index로 사용
print(close_px_all)
close_px = close_px_all[['AAPL', 'MSFT', 'XOM']]
close_px = close_px.resample('B').ffill() # 비즈니스 데이로 샘플링
close_px['AAPL'].plot()
plt.show()
close_px['AAPL'].loc['2011-01':'2011-03'].plot()
# 1월 부터 3일 데이터를 보여준다
plt.show()
app_q = close_px['AAPL'].resample('Q-DEC').ffill()
plt.show()
app_q.loc['2009'].plot()
plt.show()
- 실행 결과
| No Sampling | 2011-01 부터 2011-03 | 2009년 분기 별 |
|---|---|---|
 |
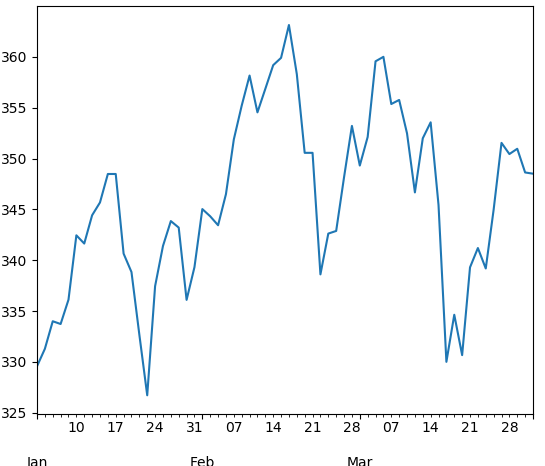 |
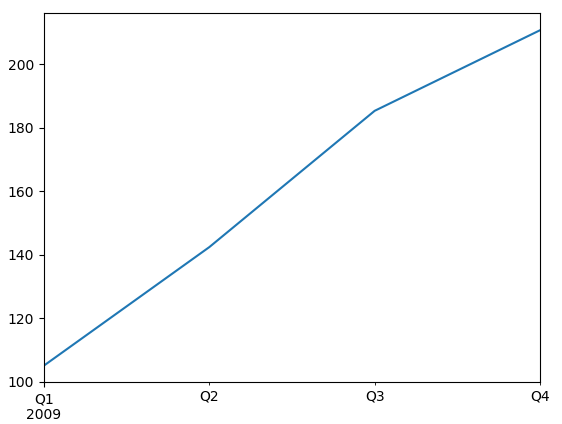 |
댓글남기기